Ongoing work on the new issue of OWASP Top 10 gives us an opportunity to perform a reality check on the data it was based on, especially order and importance of vulnerabilities. All that reduces to a simple question: how do we measure “criticality” of an application issue? Here’s how OWASP Top 10 project describes itself:
The OWASP Top Ten provides a powerful awareness document for web application security. The OWASP Top Ten represents a broad consensus about what the most critical web application security flaws are.
The first part is with no doubts true — Top 10 has gained a status of de facto standard. We have “Top 10” profiles in vulnerability scanners, most pentesting suppliers reference “Top 10” in their methodology description and it’s base for countless courses, trainings, webinars and articles.
But there’s a problem with the other part of the sentence. Specifically, the criticality ranking as defined in currently discussed version of OWASP Top 10 is based on data from seven sources. What is probably most important here is that all these sources are pentesting or scanner vendors. These companies perform simulated attack attempts on their clients’ applications and tell them what are potential attack vectors. This has significant impact on representativedness of their results — they are biased by the type of clients who use their services, and applications they submit for testing.
At the same time the sources do not include Web Hacking Incidents Database, Zone-H or <a href=http://www.imperva.com/docs/HII_Web_Application_Attack_Report_Ed2.pdf”>Imperva</a>. The common feature of these sources is that they list attack methods actually used to compromise applications in real life, not in simulated environments. And it does matter.
What is missing from OWASP Top 10 then? Most importantly CWE-98 (RFI), or more generally File inclusion vulnerabilities. Just reading Top 10, you’ll never find out about RFI/LFI, which is currently one of the most prevalent attacks on the web.
This bias was first noted in 2011 by Imperva (Why RFI get no respect) and quantitatively confirmed in their 2012 report (Imperva’s Web Application Attack Report).
I have personally noticed the same phenomenon when analyzing data from Zone-H defacements archive. Courtesy of Zone-H I had a chance to analyze their full 3 months feed containing over 170k defacement reports, out of which 89k had known intrusion method and were not mass defacements (where one vulnerability is used to compromise hundreds of websites). RFI/LFI also clearly stand out here:
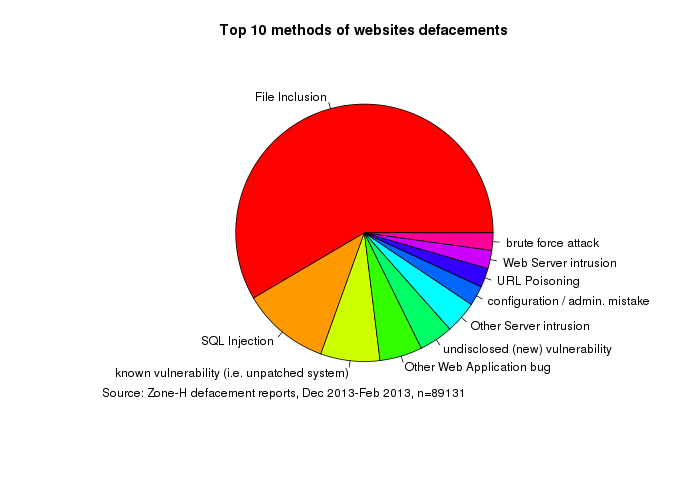
Note that it’s quite different with WHID, where RFI/LFI is almost non-existent. But WHID is built manually from published incidents and not every defacement is discussed in the news. Regardless of news coverage, there is still there are around 1 million of them each year. While majority of them may be mass-defacements (e.g. hacked VPS) the number is so large, that even if “real” break-ins are minority we should be shouting about them loud.
There’s also interesting comment from Dinis Cruz on the same topic (Should Mass Assignment be an OWASP Top 10 Vulnerability?, and I’ve just noticed Dinis posted another article: Stats used to support OWASP Top 10 entries (next version must publish them)). I don’t know the answer to question right now, but it raises exactly the same topics as discussed above:
- How do we rate the actual risk of web application vulnerabilities?
- How do we make sure this rating is backed with quantitative data?
- How do we remove expert or environmental bias from this rating? </ul> As most people realize, it's quite difficult to find detailed information on application breaches in statistically significant amounts, which makes such analysis difficult. But difficult doesn't mean impossible, and we definitely shouldn't make it worse by consciously using biased data.